GraphQL vs. REST: Qual o Melhor Para o Desenvolvimento de API?

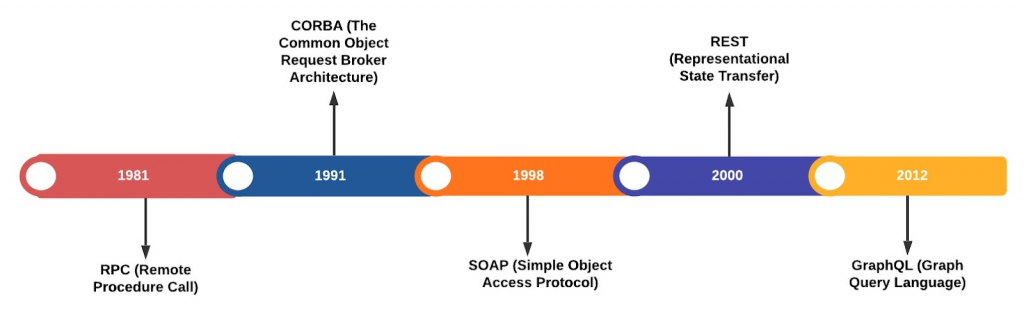
API é uma sigla em inglês para Application Programming Interface, que significa Interface de Programação de Aplicações. Ela é um software intermediário que permite que uma aplicação se comunique com outras sem precisar saber como eles foram implementados, tanto pode ser um servidor, um cliente ou um aplicativo que se comunica com um servidor. Abaixo trouxemos uma linha do tempo que exemplifica como essa interface tem evoluído ao longo dos anos, e estabelece uma excelente base de como a API pode ser construída. O REST continua sendo a ferramenta mais popular para o desenvolvimento de APIs. Porém, em 2012, o Facebook procurava algo diferente do REST e foi aí que o GraphQL (sigla em inglês para Graph Query Language) surgiu.
O que é REST?
REST é uma API de Transferência de Estado Representacional (Representational Sate Tranfer), o que significa que cada recurso tem seu próprio endpoint (ponto de extremidade). Inicialmente, o termo REST foi introduzido e definido em 2000, na tese de doutorado de Roy Fielding e foi popularizado por empresas como o Twitter em 2006. REST é um conceito de arquitetura de software baseado em rede. Ele não tem nenhum conjunto de ferramentas oficial, nenhuma especificação, não importa se você usa protocolo HTTP, AMQP, etc. O REST foi projetado para desacoplar uma API do cliente.
Os Principais Desafios do REST API
O REST API, às vezes, requer uma Maior Latência. Isso acontece quando precisamos mostrar alguns dados que devem ser consumidos de diferentes endpoints e o consumo de dados de apenas um único endpoint não é suficiente. A tabela a seguir ilustra três endpoints:
| GET /user | Busca uma lista de todos os usuários |
| GET /user/:id | Busca um único usuário :id |
| GET /user/:id/projects | Busca todos os projetos de um usuário |
E se precisássemos buscar projetos em um aplicativo cliente relacionados a um usuário específico e algumas tarefas também relacionados a este projeto? A equipe back-end precisa desenvolver algo mais? Existem algumas maneiras de fazer isso, elas são as seguintes:
- Para incluir uma consulta e depois fazer as tarefas retornar a cada projeto: GET /users:id/projects?include=tasks
- Para separar o endpoint, os recursos do projeto e pedir a um aplicativo cliente a filtragem de consulta com base no id do usuário: GET /projects?userid=:id&include=tasks
- Para incluir todos os dados possíveis associados ao usuário em um único endpoint: GET /tasks?userid=:id
Over-fetching (excesso de dados) e Under-fetching (dados insuficientes). Quando há necessidade de retornar muitos dados, o aplicativo cliente não precisa de todos esses dados. Seus clientes podem não ficar satisfeitos se forem obrigados a baixar informações adicionais desnecessárias. Por outro lado, ao reduzir o nível de informações em um servidor, outro problema pode ser enfrentado: o de consulta insuficiente (under-fetching), o que resulta na necessidade de mais um endpoint e mais recursos em um servidor para conseguir acessar os dados solicitados. A solução para é: GET /users?fields=firstname,lastname.
Dificuldade em criar versões e substituir campos que não são necessários para os próximos lançamentos. É difícil manter o REST APIs ao longo do tempo, são feitas diferentes solicitações para suportar diversas versões de aplicativos e vários clientes. É por isso que, normalmente, a v1 permanece como ela é, e a v2 é criada a partir de uma estrutura de dados mais recente. Já com GraphQL, isso pode ser feito sem controle de versões. O GraphQL retorna apenas dados explicitamente solicitados, assim, novos recursos podem ser adicionados por meio de novos tipos e novos campos sobre esses tipos sem criar um breaking change (uma ação que quebra a compatibilidade da API). O que levou à uma prática comum de evitar breaking changes contínuas e entregar uma API sem versões.
Dados imprevisíveis. Com o REST não dá para saber quais dados serão retornados do servidor, quais campos, quantos deles etc. Já com o GraphQL, o cliente determina quais campos ele deseja consultar. Não importa se é uma query (consulta) ou uma mutation (mudanças no conteúdo) — você é quem controla o que será retornado.
O que é GraphQL?
O GraphQL é um conceito mais recente que o REST, ele foi lançado oficialmente pelo Facebook em 2012 e se tornou open source (código aberto) em 2015. O GraphQL, por ser uma nova forma de solicitar dados para um servidor, é uma linguagem de consulta (query language), especificação e coleção de ferramentas desenvolvida para operar sobre um único endpoint através do HTTP, que otimiza o desempenho e a flexibilidade.
A tabela a seguir compra o GraphQL e o REST como duas abordagens de desenvolvimento de API. Em termos gerais, não podemos considerar essa comparação como uma forma de apontar qual é o melhor entre os dois, mas sim, para entender a melhor opção de acordo com a natureza do seu projeto, já que o REST é o padrão convencional para o desenvolvimento de APIs e o GraphQL é uma linguagem de consulta que ajuda a resolver problemas com as APIs. ?
A principal diferença aqui é que o GraphQL é uma linguagem voltada ao cliente. Sua arquitetura permite que o aplicativo front-end determina quais dados devem ser pesquisados e a quantidade de dados que deve ser retornada ao servidor. Já no REST, tudo é projetado no servidor, logo, o servidor é o responsável pela arquitetura.
| GraphQL | REST |
| Uma linguagem de consulta que oferece eficiência e flexibilidade na resolução de problemas comuns durante a integração de APIs. | Um modelo arquitetônico de software amplamente conhecido como um padrão convencional para o desenvolvimento de APIs. |
| Implementado por HTTP usando um único endpoint que fornece todos os recursos do serviço exposto | Implementado por um conjunto de URLs em que cada uma delas exibe um único recurso |
| Arquitetura voltada ao cliente | Arquitetura voltada ao servidor |
| Não tem armazenamento de cache automático | Tem armazenamento de cache automático |
| Sem controle de versão para API | Suporta várias versões de API |
| Apenas representação JSON | Suporta diversos formatos de dados |
| Apenas uma ferramenta é utilizada para a documentação: GraphiQL | Ampla gama de opções para documentação automatizada, como OpenAPI e API Blueprint |
| É mais difícil identificar erros pelos códigos de status HTTP | Utiliza diferentes códigos de status HTTP para facilitar a identificação de erros |
Motivos para Usar o GraphQL
Há três motivos principais que nos levam a querer usar o GraphQL em vez do REST.
- Desempenho de Rede. Ideal para quando queremos aumentar o desempenho de rede ao enviar menos dados ou somente informações necessárias e relevantes aos clientes.
- A Escolha de Projeto “Incluir Requisição x Endpoint Adicional“. A escolha mais difícil no desenvolvimento de projetos de API é incluir a requisição (including request) ou criar um endpoint adicional (creating an additional endpoint. Mas com o GraphQL, esse problema foi resolvido porque ele conta com as funções schema e resolvers. Dessa forma, o cliente tem controle dos dados que devem ser retornados.
- Gerenciar diferentes tipos de clientes. Imagine que você tenha uma API e todos os seus clientes (aplicativos iOS, aplicativos Android, aplicações web etc.) são completamente diferentes: eles precisam de uma estrutura totalmente diferente ou uma quantidade diferente de dados retornados do servidor. Com a abordagem REST, você pode criar uma API separada. Em contrapartida, com o GraphQL, você não precisa de uma API separada porque você pode ter tudo retornado de um único endpoint.
Como Começar
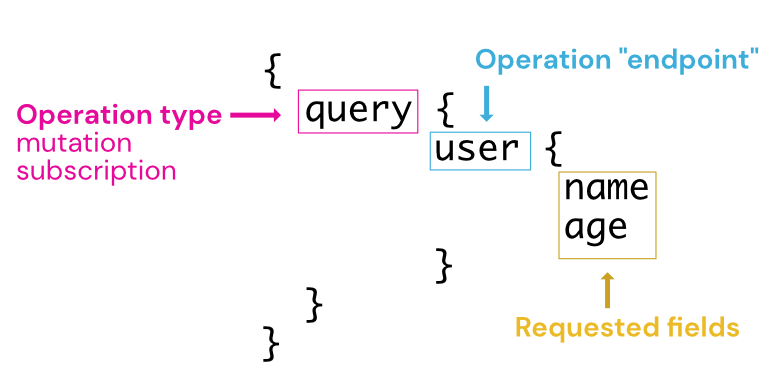
Esta é a forma como uma consulta (query) é estruturada. Três partes principais são consideradas aqui: 1) tipo de operação (operation type), 2) endpoint da operação (operation endpoint), 3) campos solicitados (requested fields).
Termos que valem à pena aprender
Seja qual for a implementação escolhida, pois há uma variedade de linguagens, ela não existe somente em JavaScript ou Node — você pode usar PHP, Python, JAVA, Go, e muitas outras. Cada linguagem de programação tem sua própria implementação de GraphQL, então você nem precisa desenvolver tudo do zero. Existem ferramentas e pacotes que podem ser utilizados, e esses termos são quase os mesmo para todos eles. Por isso, aprender o que significa esses termos pode valer a pena se você quer desenvolver uma API com o GraphQL:
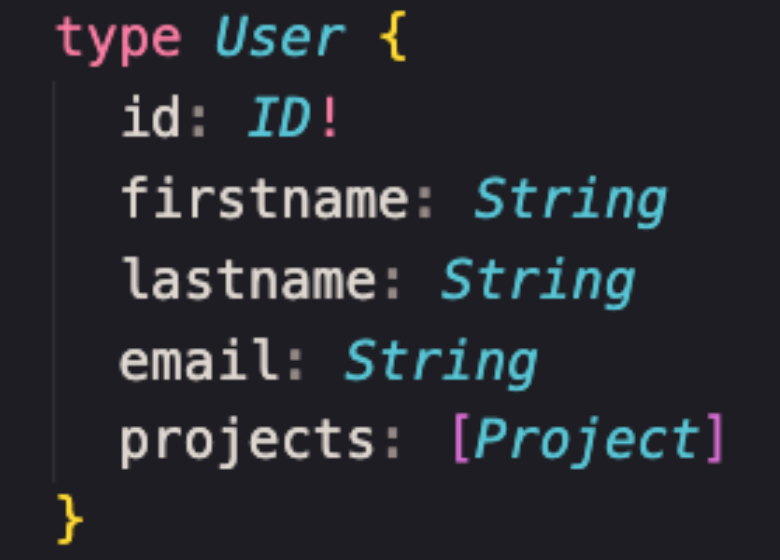
Types (tipos). O modelo de dados no GraphQL é representado em tipos, que são fortemente tipados (typed). Deve haver um mapeamento one-to-one entre eus modelos e os codigos do GraphQL. Pense nisso como uma tabela de banco de dados em que a tabela do usuário tenha campos como id, primeiro nome, sobrenome, e-mail, projetos. Coisas que valem a pena lembrar: o ponto de exclamação que indica que um identificador (id) não pode ser anulável ou, em outras palavras, é preciso ter algo no identificador por ser um campo obrigatório.
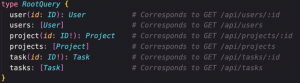
Queries (consultas). As queries definem quais consultas você pode executar seu GraphQL API. Por convenção, deve haver um RootQuery, que contém todas as consultas existentes. No exemplo, o comentário mostra como fica o restante da API. Nos parênteses entre os colchetes, vemos um argumento que precisa ser o único identificador, o que vem após s dois pontos é o tipo de usuário. Ele mostra o que deve ser retornado quando fazemos essa consulta, e depois retorna ao usuário. Logo, se consultamos um projeto, o projeto será retornado, se consultarmos uma tarefa (task), a tarefa será retornada, e assim por diante.

Mutations (mudanças de conteúdo). Se as consultas (queries) são solicitações (requests) GET, as mudanças de conteúdo podem ser vistas como solicitações POST | PATCH | PUT | DELETE que modificam os dados. O exemplo traz mudanças de conteúdo de “createUser” (criar usuário), “updateUser” (atualizar usuário), “removeUser” (remover usuário).
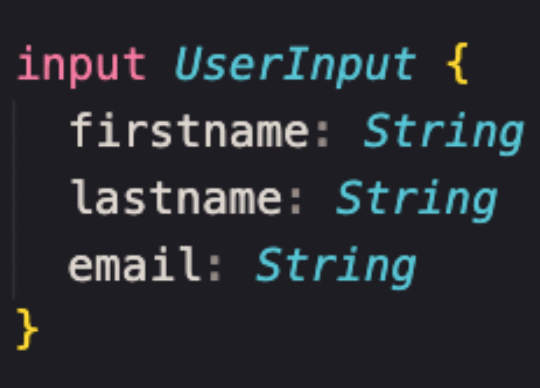
Input (entrada). o tipo UserInput é um tipo de Usuário (User type) sem id e campos de projetos. Note que a palavra-chave é input e não type. Imagine que ele seja um formulário em uma página em que você precisa preencher alguns dados e quais os tipos de informações necessários para criar um perfil de usuário.
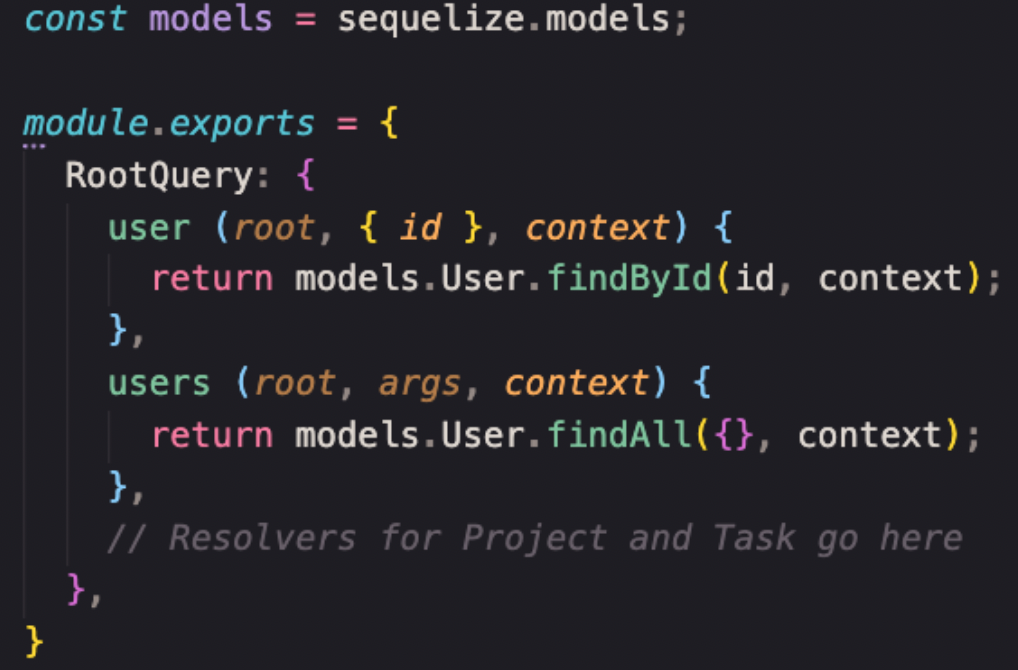
Resolvers. Como o próprio nome sugere, a função resolver dá um conjunto específico de instruções para converter as operações do GraphQL em dados. Ele é basicamente uma função de controle, a lógica do que tem que ser retornado (resolvers for queries) quando essa consulta é feita e o usuário solicita os dados, já os resolvers para mudanças de conteúdo (resolvers for mutations) são utilizadas quando o usuário busca atualizar ou deletar os dados.
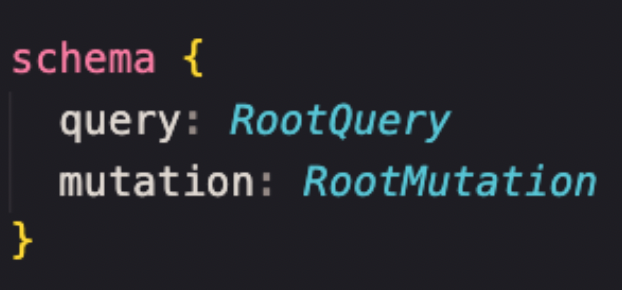
Schema (esquema). Definimos o schema do GraphQL por meio de tipos, consultas e mudanças de conteúdo, que é o que o endpoint do GraphQL mostra ao mundo.
Materiais que valem a pena conferir
Aqui vão dois materiais fundamentais para se aprofundar mais no campo do GraphQL (ambos em inglês):
- GraphQL.org. Dedicado a ensinar todos os conceitos básicos e as reais especificações do GraphQL.
- Como desenvolver no GraphQL? Dedicado ensinar implementações. Por exemplo, se você quer saber sobre o servidor Apollo, ele te dá uma boa base de quais frameworks front-end podem ser usados para consumir os dados daquela API. Não precisa usar nenhuma ferramenta ou biblioteca para os frameworks front-end para consumir a API — você pode fazer uma solicitação XmlHttp normal, mas você precisa fazer uma solicitação POST para esse endpoint e fornecer a consulta no corpo (body), que é o GraphQL.
O servidor de API GraphQL pode ser usado como um gateway para outros microsserviços ao falar diretamente com o banco de dados ou outras APIs REST. Assim, você pode ter várias APIs REST, obter dados e fazer uma fonte única de verdade (SSOT, sigla em inglês).
Este artigo foi inspirado na apresentação do desenvolvedor front-end, Gediminas Survila: “GraphQL vs. REST: Which is the best for API Development?” [GraphQL vs. REST: Qual o melhor para o desenvolvimento de API?]

Bruna Vidanya é tradutora na Hostinger Brasil. É graduada em Letras Tradução Inglês pela Universidade de Brasília e já foi estagiária tradutora no Senado Federal. Teve a sua primeira tradução – um livro infanto-juvenil – publicada pela Livraria Senado Federal. É apaixonada por tecnologia e agora demonstra essa paixão, com muito carinho, escrevendo e traduzindo artigos para a Hostinger. Nas horas vagas, Vidanya ama ficar com os seus três cachorrinhos: Madonna, Snoop e Scooby-Doo, além de ver séries (as sitcoms são as suas favoritas). Um fato curioso sobre a autora: seu primeiro bichinho de estimação foi um galo Garnisé, chamado Chico Liro.


